
Baby, It’s Warm Inside
Temperature and Large Language Models


In two of our previous posts (randomness and structured output) we talked about some of the details of how LLMs generate text. In this post we’ll go deeper into one of the more misunderstood properties of LLMs: Temperature. How it can be used to influence generated tokens, how it relates to the Top-P parameter, and what settings work best for which applications.
At their core, LLMs are pattern recognition systems trained on vast amounts of text data. When generating text, they work by taking a sequence of text and predicting the next token (think of this as a word or part of a word) based on the preceding text.
For each possible next token, the model generates a probability score based on what it learned during training. To give a specific example, if you asked it to complete the sentence “The quick brown fox jumped over the lazy…”, it would give an extremely high probability that the next word is “dog”, based on how frequently this phrase comes up in English.
Now you might think that the best approach to generating text would be simply to choose the highest probable word at each step and you would have “perfect” text, but this is not always the desired outcome. In fact, the results usually end up sounding robotic. Fortunately it turns out that just by varying the choices a bit, the resulting text will be given a much more human feel.
Enter Temperature
Temperature is one method of providing that variability. It’s sometimes described as setting the “creativity” of an LLM but that’s an oversimplification. Instead it really changes the probability distribution of its choices. Let’s take a look at an example.
We’ll begin with the phrase, “The snowflakes were falling gently…” and see what the most likely probability for the next word is:
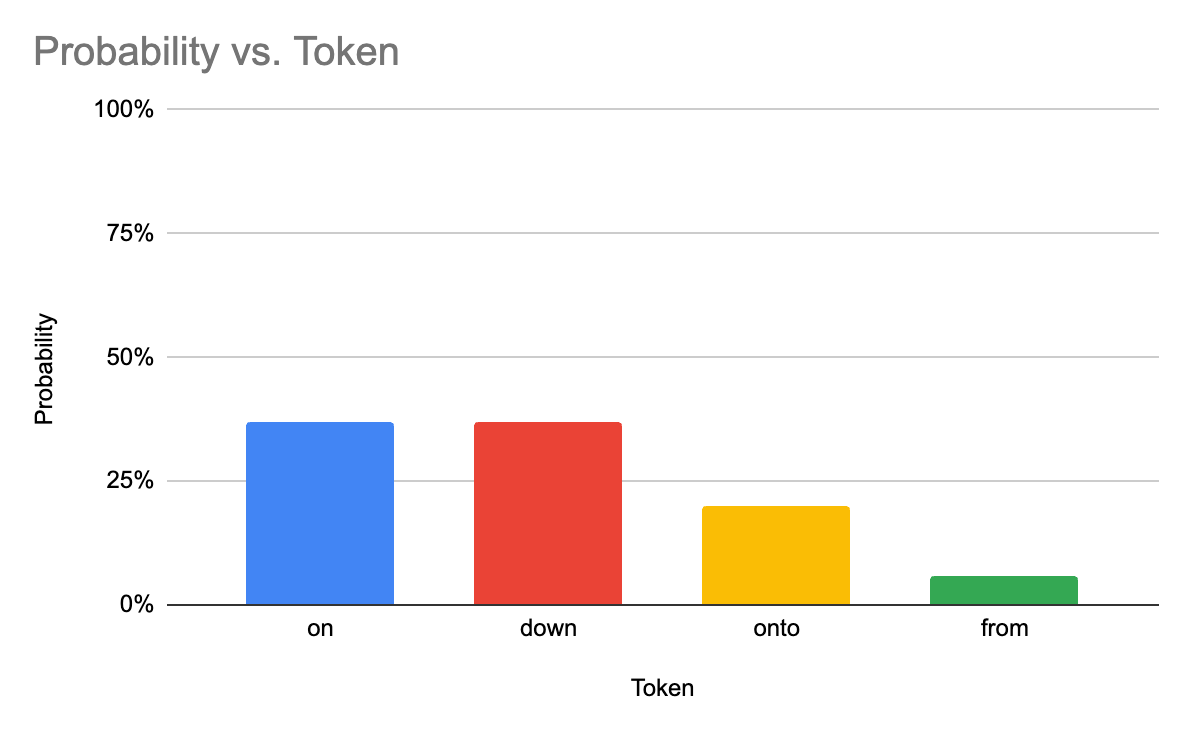

By default, gpt-4 has the temperature set to 1.0, but if we were to bump it up to 2.0, we’d see a different distribution:


As you can see, the top options drop in likelihood, and the lower-probability options increase significantly. Over the course of an entire response, this change results in substantially different text.
A temperature of 0 indicates that each probability should be forced to one extreme or the other. In the table above, the word “on” and “down” would maximize their probability, since they were tied and had the largest probability to begin with. All others would drop to a probability of 0%.


Note that temperature is only affects the probabilities, not accuracy per se. Setting the temperature to 0 won’t prevent hallucinations but will make the LLM's output more predictable.
What temperature should I use?
It depends on your application, but there are some basic rules of thumb for where to start. These temperature values are for OpenAI’s API; other providers may be different.
0 - 0.5: Use a low temperature for applications requiring more deterministic output, like generating database queries, solving math problems, or writing code.
0.6 - 1.0: A medium temperature is good for conversational applications, especially when seeking accuracy. There is enough variance in the output to sound natural but it still remains focused. This is a good place to start for a chat application or a blog writer.
1.0 - 1.4: Higher temperatures can be good for ideation as the model generates more unexpected results. This is a good place to start if you need novelty in your output, but likely requires human supervision.
> 1.4: The highest temperatures will likely produce incoherent responses. The LLM will often generate nonsense, as we saw in our earlier essay on randomness.
Top-P
An alternative to temperature is top-p. The P stands for “probability” and it’s sometimes known as “nucleus sampling”. Essentially it works by defining the probability cutoff for the selection, rather than altering the probabilities of all the possible next tokens. For example, if in the first example we defined a top-p of 0.75, we would get the possibilities that add up to 75%; in that case just “on” and “down” since they add up to 74%.
A high value of top-p, but smaller than 1.0, allows for variety in the responses while ensuring that some of the more esoteric response options will be excluded. Note: OpenAI’s documentation doesn’t recommend mixing temperature and top-p, but it’s not disallowed.
Let’s try a couple of examples:
Given a prompt of “Write a single-sentence story about a man on a desert island”, we get the following:
Low temperature (0.0):
“Stranded on a deserted island, the man discovered a message in a bottle that revealed he was not as alone as he thought.”High temperature (1.4):
“Surrounded by the shifting sands of time and solitude, the man on the deserted island carved wood into company, weaving stories hope thicker than fear into logs pounding cheerfully with relentless surf.”Low top-p (0.5):
“Stranded on a desert island, the man discovered a message in a bottle that revealed the secret to his escape.”High top-p (0.9):
“Stranded on a deserted island, the man discovered a hidden waterfall that sang the secrets of survival in whispers of the wind.”
As you can see, increasing the temperature or top-p increases the variety of our responses but in different ways. A high temperature will rapidly lead to incoherence, while a high top-p keeps things a bit more understandable.
Takeaway
LLMs aren’t a complete black box when it comes to controlling their output. In addition to good prompt engineering, there are additional knobs that control their responses. Temperature and top-p aren’t one-size-fits-all settings, but are worth investigating if you need to fine-tune behavior. Remember that even at their most constrained, LLMs are still making predictions based on patterns. You have the ability to make them more or less conservative about which paths they choose to follow.
These controls not only help you refine outputs but also serve as essential tools for debugging LLM responses, providing insight into why specific outputs are generated.
Learn more about LOGIC, Inc at https://logic.inc