
Getting gpt-4o-mini to perform like gpt-4o
Few-Shot Knowledge Distillation


Routing and Distillation
We’d like to share an LLM architectural pattern that we’ve found success with for dividing tasks between large and small language models. For many tasks, it allows us to use smaller foundation models, like gpt-4o-mini, while maintaining gpt-4o levels of capability. And there’s no fine-tuning involved! We show a 63% cost reduction without any loss in performance by taking advantage of high-precision few-shot examples.
The pattern exploits the few-shot learning capabilities of smaller models—quickly adapting to slightly new but well-defined tasks with just a handful of examples—and the zero-shot reasoning powers of larger models, which can handle completely novel instructions with no explicit training. We share a case-study below measuring the impact of this on real-world data and tasks.
Our pattern takes notes from two of the most common strategies for models collaborating on work together:
Task Routing
A smaller model handles requests by default and only when a task exceeds some uncertainty or complexity does it escalate the request to a larger model. This approach can significantly reduce the computational overhead for average queries, since the larger model is only invoked when necessary. The models may even be running on different devices (e.g. a small model running on your phone and a large model running in a datacenter).
Knowledge Distillation
A large “teacher” model trains a smaller “student” model. Over time, the student model can learn to mimic the teacher’s performance on specific tasks at a fraction of the computational cost. This helps produce smaller models that can more confidently handle specific tasks independently.
In some ways, these two approaches choose opposite trade-offs: One pattern always starts with the smaller model, the other pattern always starts with the larger model. One pattern keeps the models general, the other pattern creates a task-specific model.
We combine both approaches into a pattern we refer to as Few-Shot Knowledge Distillation (FSKD)– which attempts to take advantage of the generalized reasoning capabilities of large foundation models, while allowing smaller foundation models to rapidly and dynamically learn task-specific lessons from their larger counterpart.
Novelty Score
At the heart of Few-Shot Knowledge Distillation is the Novelty Score. This is a simple metric that tells us if we’ve seen a similar task many times before (low novelty) or if we’ve rarely seen anything like it (high novelty). We assign a score to every new task that comes in and then choose whether we use a large model or a small model.
There is one important pre-requisite: Every time a large model (the “teacher”) handles a task, you must index an embedding of the task, while storing the task and answer.
To compute the novelty score, when a new task comes in, search for semantically similar historical tasks. If you find enough that exceed some threshold, classify this task as “low novelty”. If you don’t find enough historical semantically similar tasks, classify it as “high novelty”.
High novelty tasks always get routed to the larger language model.
Low novelty tasks get routed to the smaller language model, along with the historical tasks/answers, which are provided as few-shot examples.
In this way, once the large language model has performed a task a sufficient number of times, we allow its historical work to be used to teach the smaller model on demand.
There are two parameters to the novelty score function that you can adjust according to your needs:
similarity threshold– how similar an entry needs to be to be considered a matchmatches threshold– the number of matches needed to be considered “low novelty”.
Formally, we’d define it as:
where:
T is a task for the LLM
θ ∈ ℝ is the similarity threshold for matching historical tasks
m ∈ ℤ is the threshold for determining high or low novelty
search(T,θ) retrieves historical tasks that are semantically similar above the θ threshold.
And our llm call becomes:
where:
T is a task for the LLM
θ ∈ ℝ is the similarity threshold for matching historical tasks
m ∈ ℤ is the threshold for determining high or low novelty
search(T,θ,m) retrieves the first m historical tasks that are semantically similar above the θ threshold.
teacher(T) passes the task along to the teacher model and semantically indexes the result to later be retrieved by search.
student(T, fs) passes the task and few-shot examples along to the student model.
You’ll find that for many real-world use cases, the performance of calling FSKD is indistinguishable from or superior to always calling the larger teacher model, even though overtime you may wind up calling the smaller student model substantially more.
In the case study below, this technique reduces calls to the teacher model by 70%, without any reduction in quality and saving 63% in cost.
Real-World Case Study: Moderating Inventory
At LOGIC, Inc. we specialize in automating business workflows with LLMs.
The tasks are highly varied across our customers and we need reliable mechanisms that give them the best performance, cost, and latency possible for their tasks. Many of these processes may change regularly, so we wanted to provide a mechanism to achieve this without the overhead and trade-offs that come with fine-tuning a model every time the process gets updated or the distribution of inputs changes.
We ran a case-study with one of our earliest adopters, Garmentory, which is a fashion and home goods marketplace that helps independent fashion designers and boutiques sell their goods online. The inventory that Garmentory ingests comes from 3rd parties, so the titles, descriptions, colors, sizes, taxonomies, etc. all vary wildly. They have a large document that describes, with great nuance, how this inventory should be moderated and normalized to be consistent. We teamed up with them to use LLMs to automate their moderation pipeline.
Experiment
We ran this experiment on 1,000 moderated inventory items using gpt-4o, gpt-4o-mini, and FSKD, providing the exact same instructions to each. For the FSKD parameters, we use a similarity threshold of 0.8 with a matches threshold of 3.
We then use an evaluator to measure 1) how consistent the model’s response is with a known expert answer and 2) was the FSKD answer better, worse or equivalent to the other models’ outputs.
We then also look at the impact FSKD has on cost and token usage.
Consistency with the Expert
The moderation process is fairly subjective, so we use a reference “expert” answer as a baseline to compare the results to. Notably, any given moderation result isn’t necessarily right or wrong, but rather it’s a gradient. For example, a moderator might have fixed up the product title and description, but missed normalizing the sizes or colors. Or maybe they forgot to remove miscellaneous HTML tags from the description, but everything else was correct. As a result, we don’t think of this as a strict “right” or “wrong”, but simply “Did this result deviate meaningfully from the expert?”.
For each inventory item, we take each model’s answer and ask an evaluator to determine:
How well does this submission match the expert answer?
A: The submission is perfectly consistent with the expert answer.
B: The submission is mostly consistent with the expert answer, with minor deviations.
C: The submission has meaningful deviations from the expert.
Small Model
Let’s first look at the smallest model’s consistency with the expert. This will give us a sense of how difficult the task is.
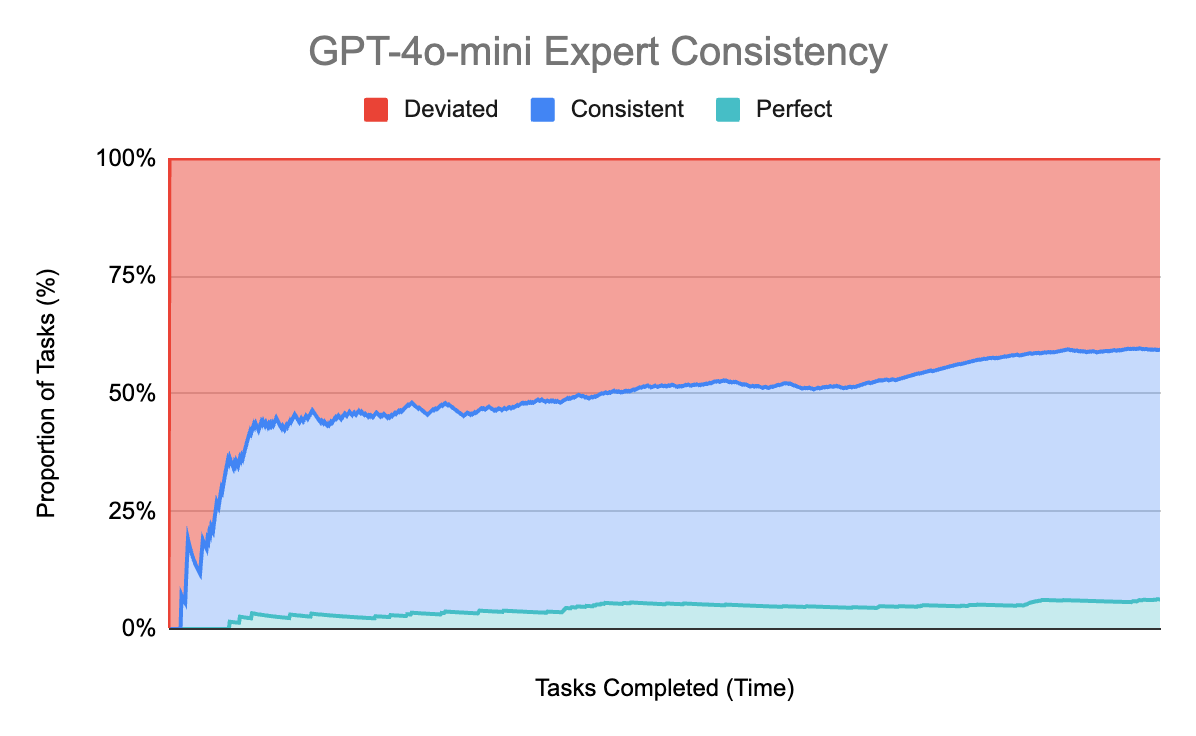
We see that gpt-4o-mini only gets expert-like answers about 60% of the time. It rarely gets a perfect answer (6.3%).
Large Model
Can the larger gpt-4o model do any better at the moderation task?
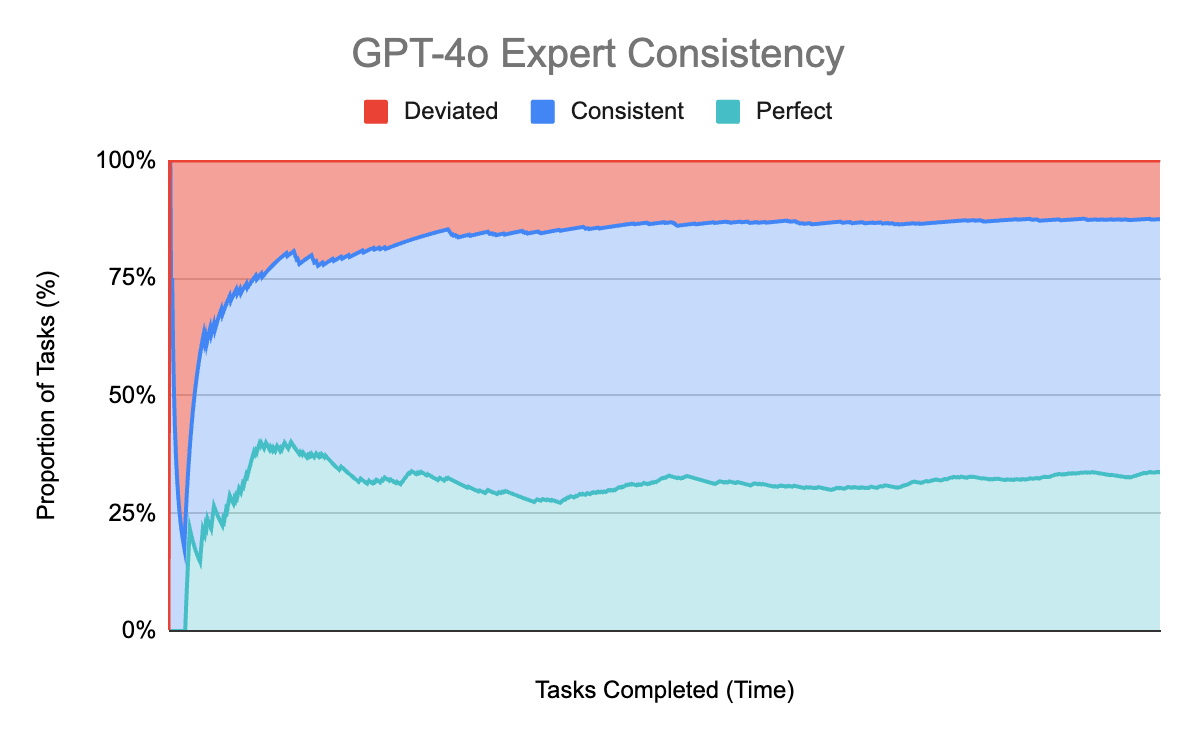
gpt-4o performs much better at being consistent with the expert answer – 87.6% of the time. It even gets it perfect 33.9% of the time.
FSKD
How well does our FSKD approach work?
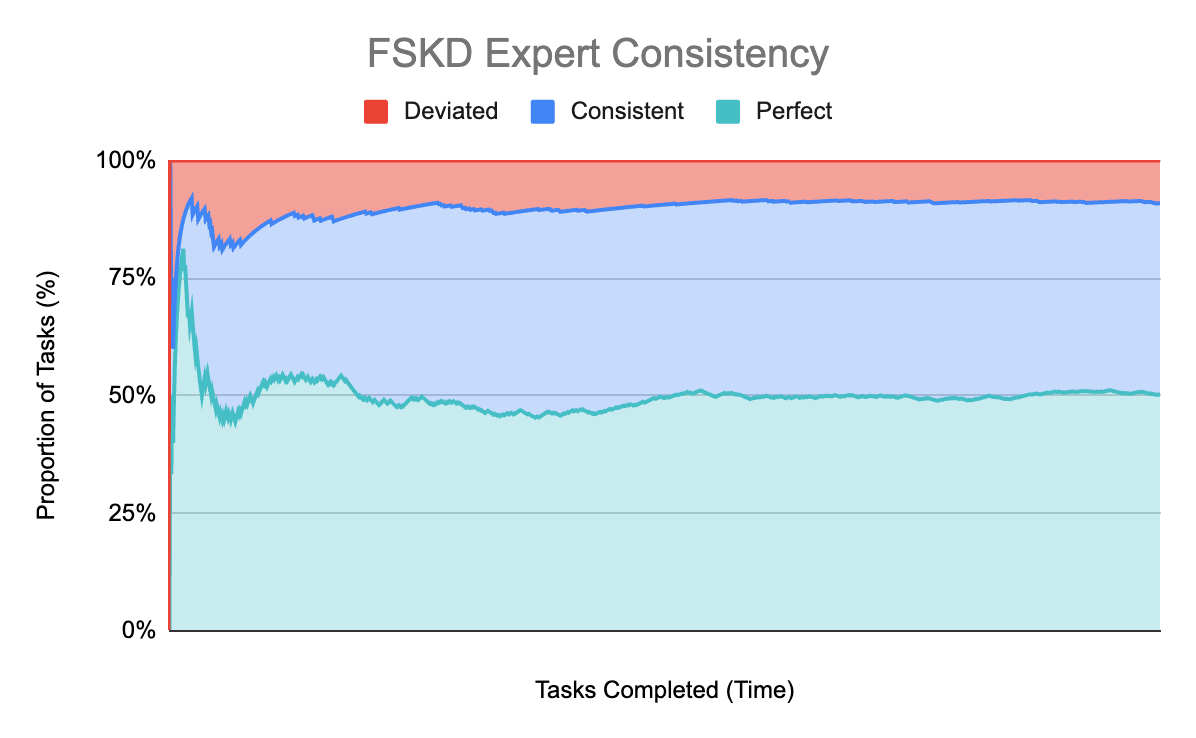
Remarkably, FSKD gives an expert-consistent answer 90.9% of the time, with 50.3% being perfectly aligned with the expert.
When running this though, 68.7% of those tasks were routed to gpt-4o-mini, the same model that struggled so much above. The difference is that this time we supplied high-precision few-shot examples drawn from the historical tasks. That small little tweak allowed us to surpass gpt-4o performance while using a much smaller model!
When we first start calling FSKD, we always route to the teacher model (gpt-4o), but as soon as we start getting some examples, we rapidly begin routing over to the student more and more. Let’s look at how many LLM calls we route to the teacher vs the student over time:
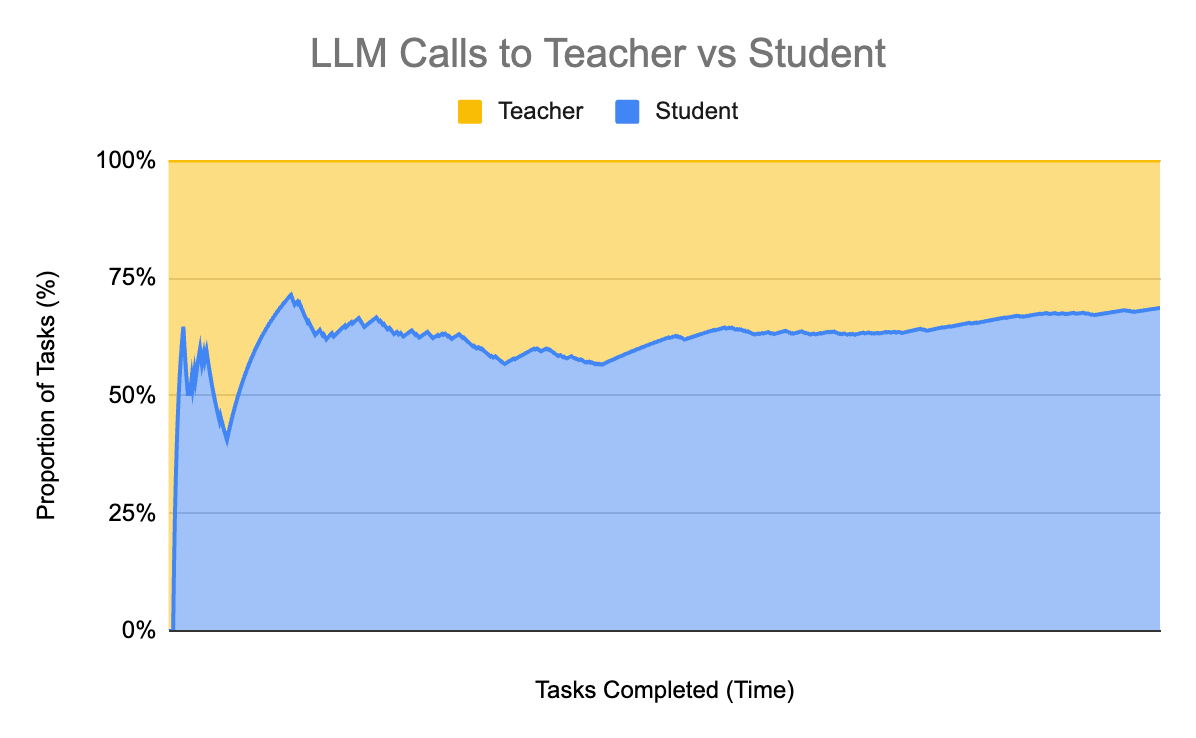
One of the great things about this architectural pattern is that if the input tasks suddenly change substantially, and we don’t have enough examples for the student to use, we’ll just fallback to the teacher until we’ve gathered enough examples for the new kinds of input. It’s a self-governing and adaptive pattern.
Another nice property of FSKD is that you can tweak the similarity and matches thresholds to influence how aggressively tasks get routed. This allows you to easily optimize for cost, speed, or quality as needed.
The Winner
The second dimension we evaluated was putting the models head-to-head and rating which model provided the better answer. We asked our evaluator, with blind and randomized submissions:
Which submission is better?
A: Submission 1 is a more accurate answer than submission 2.
B: The two submissions have no meaningful distinction.
C: Submission 2 is a more accurate answer than submission 1.
Large vs Small
As a baseline, let’s first consider the two foundation models directly, without any FSKD.
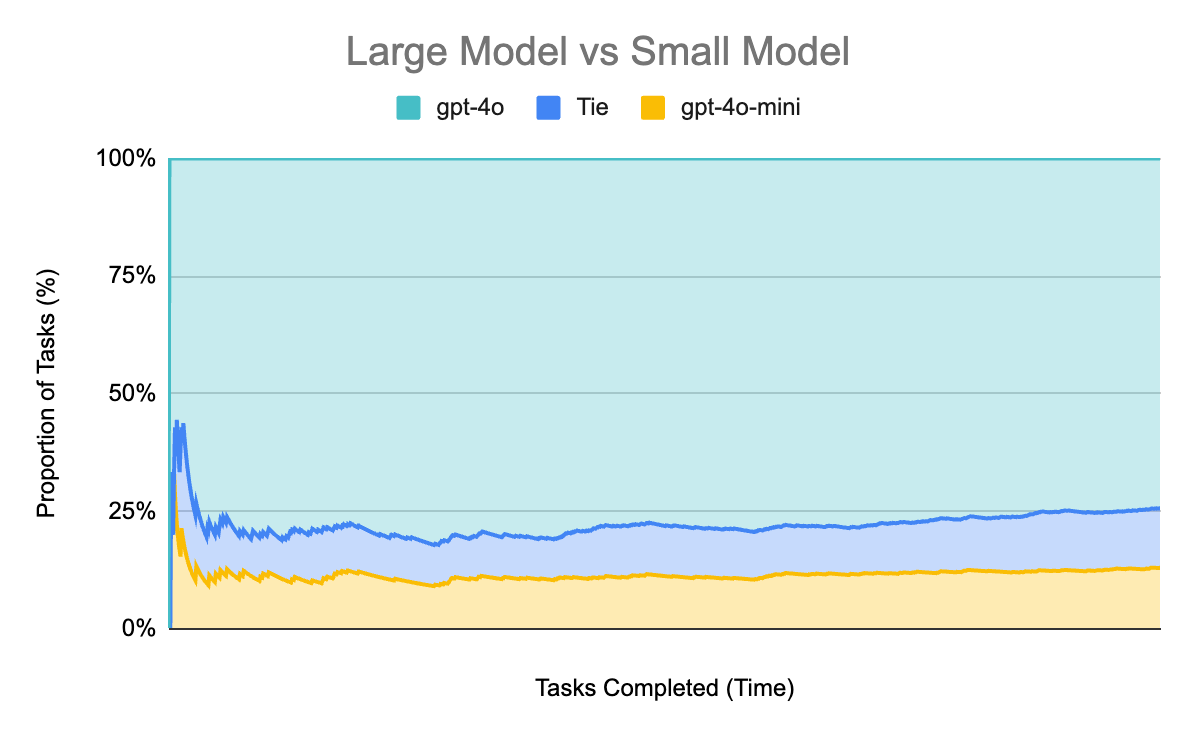
Unsurprisingly, the much larger model regularly beats (74.3% of the time) the much smaller model. In 12.6% of cases they tie and in 13.1% of cases gpt-4o-mini wins out over gpt-4o.
FSKD vs Small
By this point, we shouldn’t be surprised that fksd also handedly beats gpt-4o-mini:
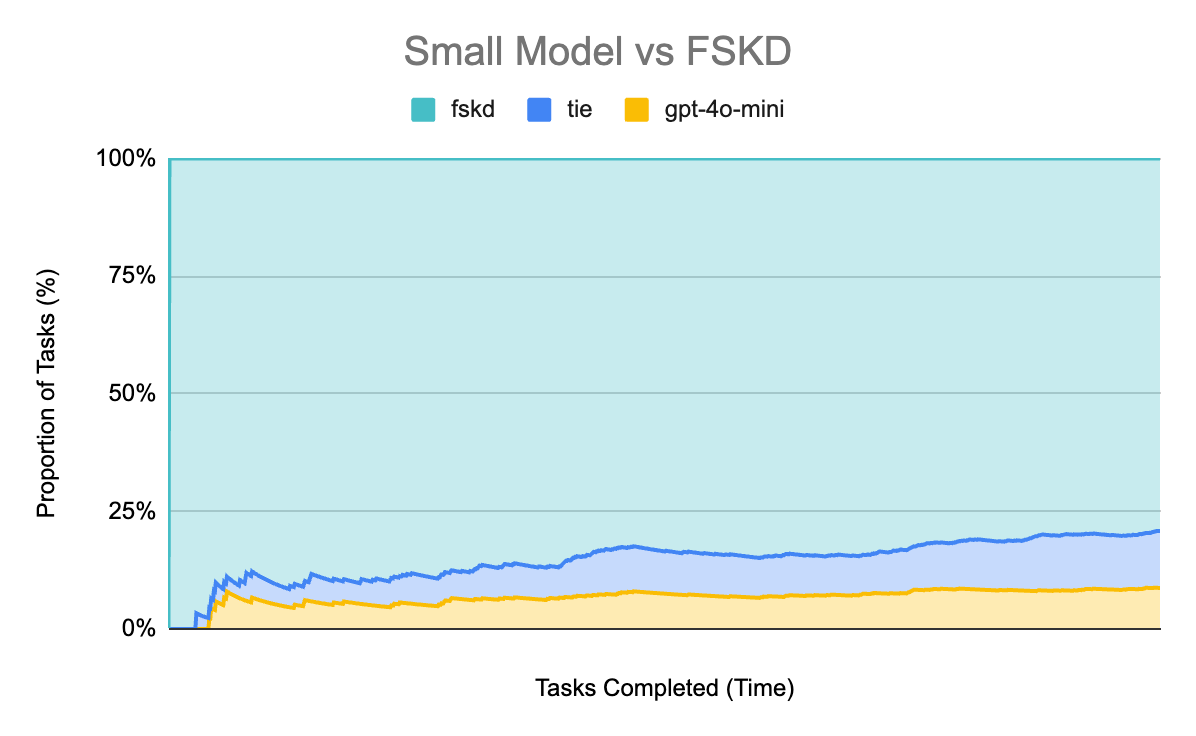
FSKD surpasses the performance of gpt-4o in terms of answer preference over gpt-4o-mini. We see FSKD is preferred in 79.2% of cases, and ties in another 12.1% of cases. Only in 8.7% of cases were the gpt-4o-mini answers preferred.
FSKD vs Large
And, finally, does the FSKD approach generate answers that are more preferable than gpt-4o answers?
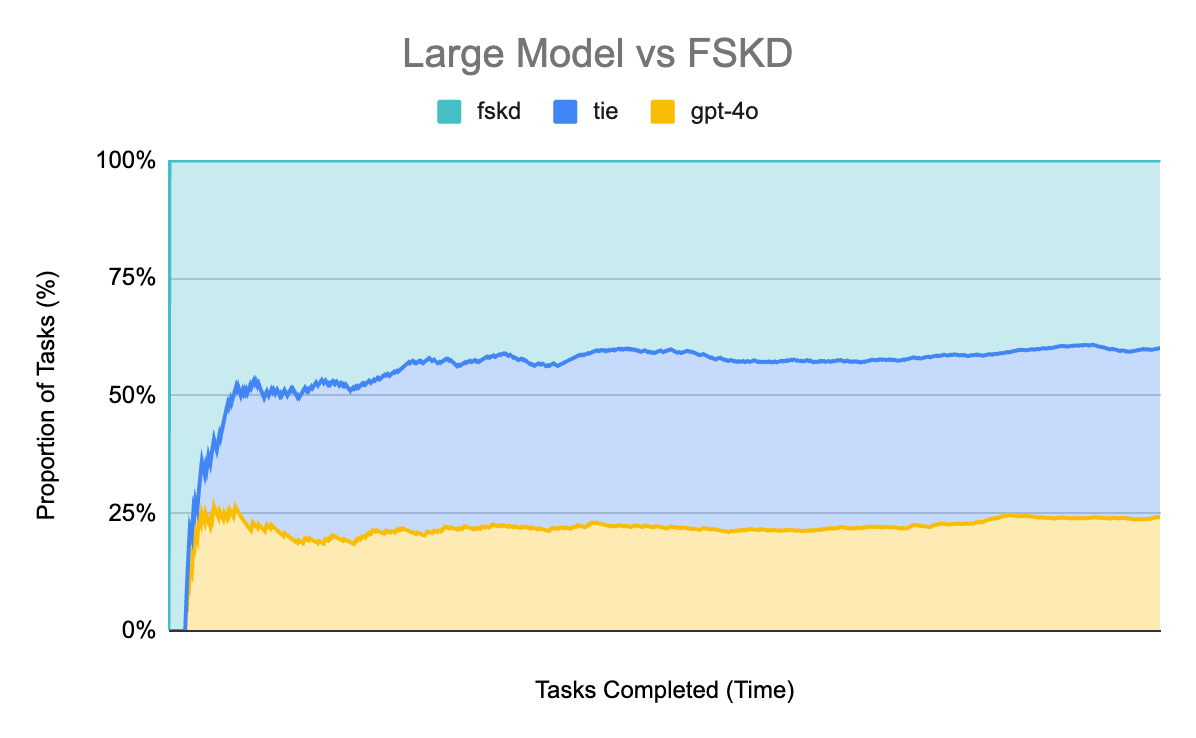
It’s a much closer result, but FSKD ties or beats gpt-4o in 75.9% of the tasks.
Cost Impact
These results are promising, but are we reducing costs? It’s true that we’re sending ~70% of our requests to a cheaper model, but we’re also sending far more tokens because we’re now including few-shot examples in our requests.
How does the cost break down in practice?
As a reminder, there’s three classes of tokens:
output – these are tokens that are generated by the model, and are relatively expensive vs input tokens.
input uncached – these are new input tokens that we haven’t sent before.
input cached – these are tokens that OpenAI has cached because we’ve recently sent them. These are cheaper than uncached tokens.
Tokens Used
We would expect the FSKD method to use about the same number of output tokens as the large model (gpt-4o), but it should use substantially more input tokens because we’re adding multiple large few-shot examples in each task. And that’s exactly what we see:
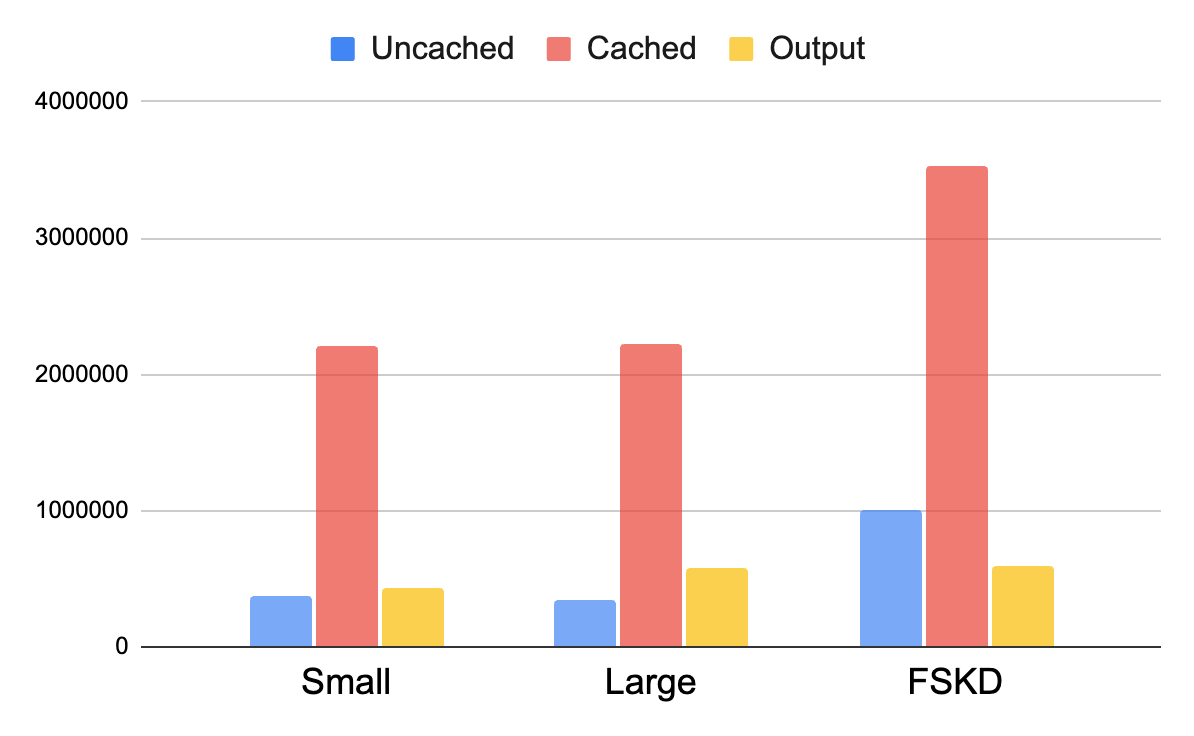
We see that we used about 1.6x as many cached tokens and 2.9x as many uncached tokens, but all of those extra tokens should be getting routed to the smaller cheaper model, since that’s the only path that gets the few-shot examples.
To fully understand the cost impact, we need to further break down how tokens are divided between the two models when using FKSD. Let’s look at that:
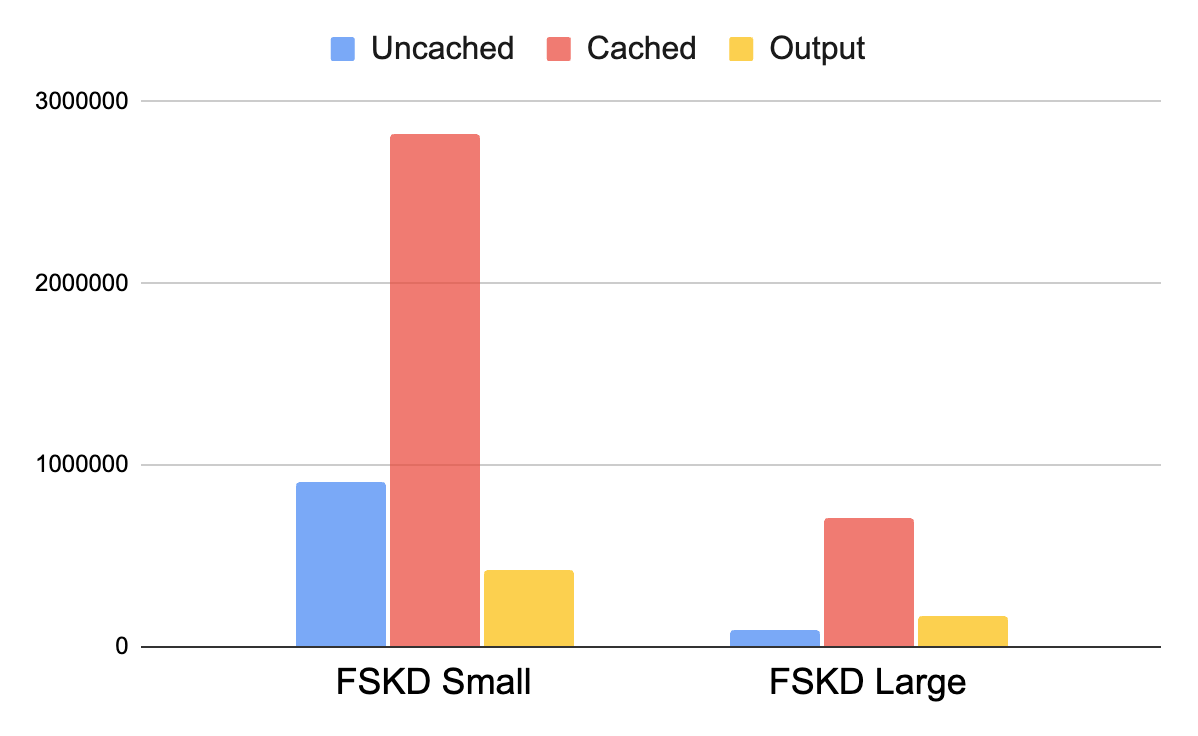
Fortunately, the vast majority of those tokens (80.9%) are for the small (gpt-4o-mini) model, suggesting there might be a nice cost savings, even though the total tokens used by FSKD is much larger.
Total Cost
When we sum of the blended cost of cached, uncached, and output tokens across all of the different models we see a meaningful reduction:
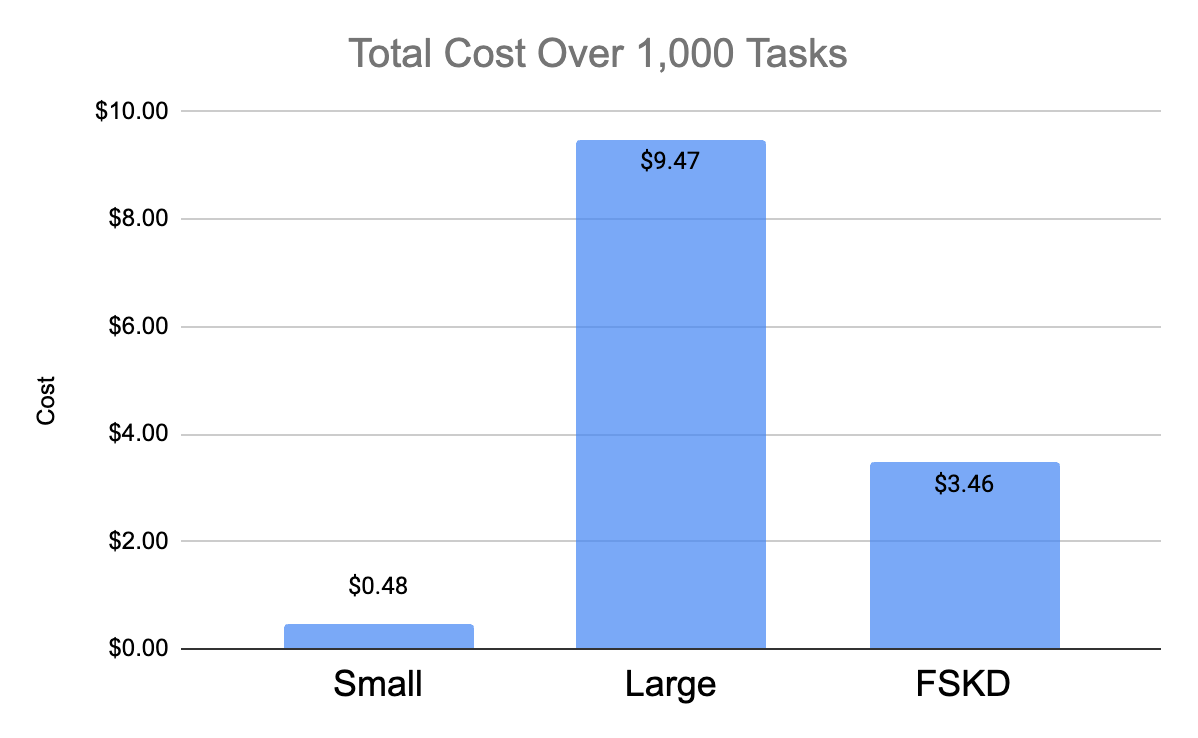
We find that with FSKD, we get gpt-4o levels of performance while being 63.4% cheaper.
And since FSKD has levers to tweak – the similarity and matching thresholds – we can change those to be more or less aggressive as needed. For example, if we reduce our similarity threshold from 0.8 to 0.6, we wind up routing 96.8% of calls to the small model:
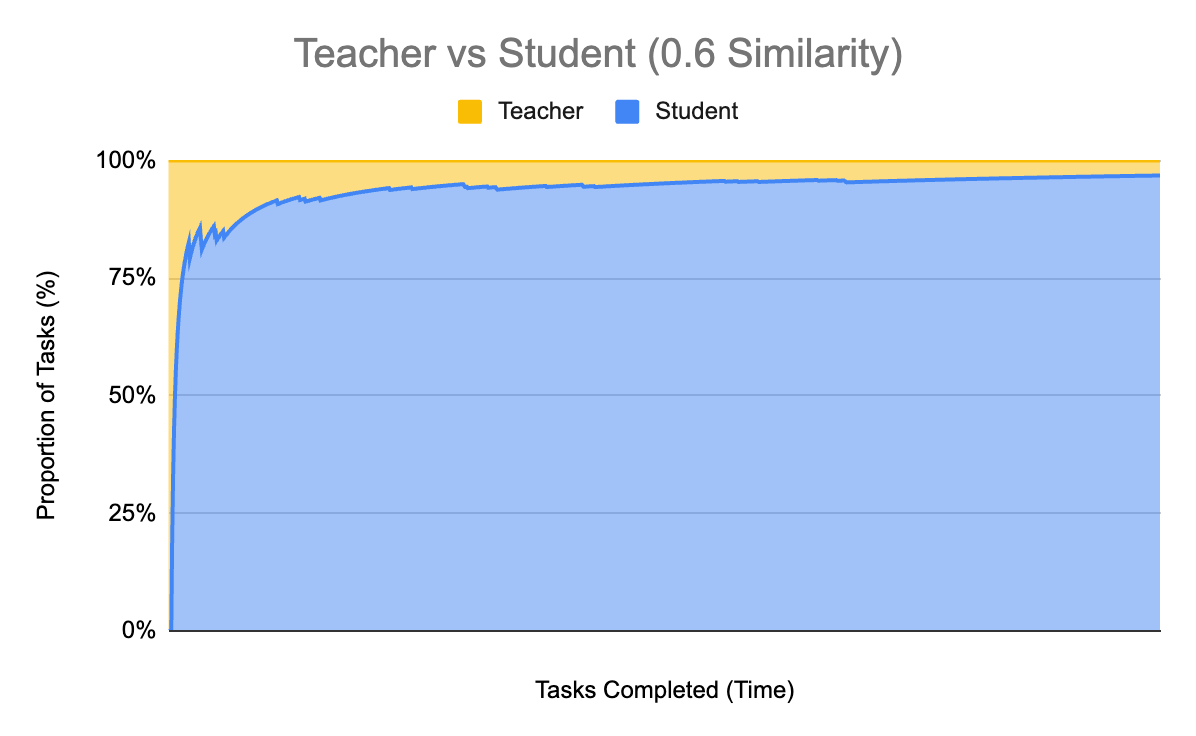
However there’s a large quality trade-off: FSKD only meets or beats gpt-4o in quality for 40% of cases now and gpt-4o-mini in 72% of cases (as opposed to 75.9% and 79.2% from before). The upside is that the cost plummets to just $1.06, saving 89% over gpt-4o and costing only twice as much as gpt-4o-mini.
These levers allow you to make the exact trade-offs that your personal requirements and budget requires.
Future Publication
This case-study represents a single data-point from a larger study we plan to publish in 2025, covering a broader number of models, benchmarks, and permutations. If you’d like to follow along, we’ll be sharing it here at https://bits.logic.inc. Subscribe to stay up to date.
Learn more about LOGIC, Inc. at https://logic.inc