
It's beginning to look a lot more readable.
LLMs will usually perform better with human-friendly inputs and outputs.


The most common piece of advice we give to folks who are struggling with getting an LLM to reliably perform a task is to rewrite that task to be more human-friendly. Whether it’s the input you’re sending to the LLM or the response you’re getting back from the LLM – making both more human-friendly will usually result in better outcomes.
You’d be amazed at how simple tweaks like asking the LLM to pretty-print JSON rather than output it on a single line can meaningfully improve outcomes.
Write Friendly Instructions
When it comes to inputs for the LLM (a.k.a. your prompt), we find it helpful to think about how well-structured Standard Operating Procedures (SOPs) are written. These are documents that are designed to guide (often hundreds of) humans on how to perform a task or process. And the same sections that go into a good human SOP also go into a good machine SOP.
They should have sections such as:
Purpose and Scope – A clear statement explaining why this procedure exists and what it aims to accomplish. This section should answer the question "Why do we need this SOP and what are the limitations and exclusions?”
Definitions – Clear explanations of technical terms, acronyms, specialized vocabulary, equipment references, system names, etc.
Procedure – Detailed narrative of the process, including sequential steps in chronological order, decision points and conditional actions, critical control points, quality checks, and expected outcomes.
Examples and Scenarios – Detailed examples of typical cases, edge case examples, sample inputs and outputs, before/after comparisons, and common error scenarios with resolutions.
All of these sections should be present in both human and machine-oriented SOPs. We touched on a similar theme in our post on automating runbooks:
… even though runbooks are written for human consumption, they have many components that map directly to components of good LLM prompts as well.
People often try to take shortcuts when writing their LLM instructions, and if it’s a one-off request with a human present to make corrections, it’s usually fine. But when you have an LLM regularly performing a task (e.g. millions of times in a row), try to think about how you would write down instructions for a team of humans to perform that same task reliably and then apply that same thinking to your instructions for the LLM.
A recent real-world scenario we ran into involved a document with a massive unordered table of 1,500 rows. We asked “How would we alter this to make it easier for a human to quickly reference?”. We first sorted the table based on the primary lookup criteria. We then further subdivided the table into smaller, more focused tables placed into dedicated sections within the document.
The end result was that the table was in easier to reference sections, with easier to scan through rows. The LLM was immediately able to work better with that document – as were the humans that were also testing it.
Ask For Friendly Results
Similarly, if you’re struggling to make sense of the output an LLM is generating, the LLM is probably having difficulty generating it. Ask it to pretty-print the output, or ask it to generate a well-formatted markdown file.
One of the use cases we heavily rely on at LOGIC is using an LLM to generate valid blobs of JSON. Every LLM call we make involves JSON. For example, every time we get a new business document (e.g. an SOP or PRD), we generate a JSON schema that describes the business process outlined in that document. And then we use that schema to guide future generative output, such as generating compliant test cases. This, combined with OpenAI’s Structured Output (we’ve written about about here), gives us a reliable way to generate inputs and outputs for that process.
Sometimes, however, we can’t use structured output to ensure valid JSON. For example, the JSON Schema specification is too complex for OpenAI’s structured output to support. So in scenarios like generating a valid JSON Schema definition, we need to fall back to other mechanisms. What we’ve found is that LLMs can run into complexities generating large, nested JSON, but they are significantly more reliable when asked to generate pretty-printed output. Similar to how a human writes JSON by hand, they’re more accurate when they can use lines and indentation to help keep track of the nesting.
You can try this yourself. With ChatGPT-4o (o1 also fails, but takes longer and requires additional levels of JSON nesting), try prompting with the following:
Can you give me a deeply nested json example with a Santa North Pole factory theme? Just write it on a single line without whitespace for easier testing.This is a non-deterministic process and will likely succeed sometimes, but within a few tries you’ll get back a deeply-nested incorrect JSON example:
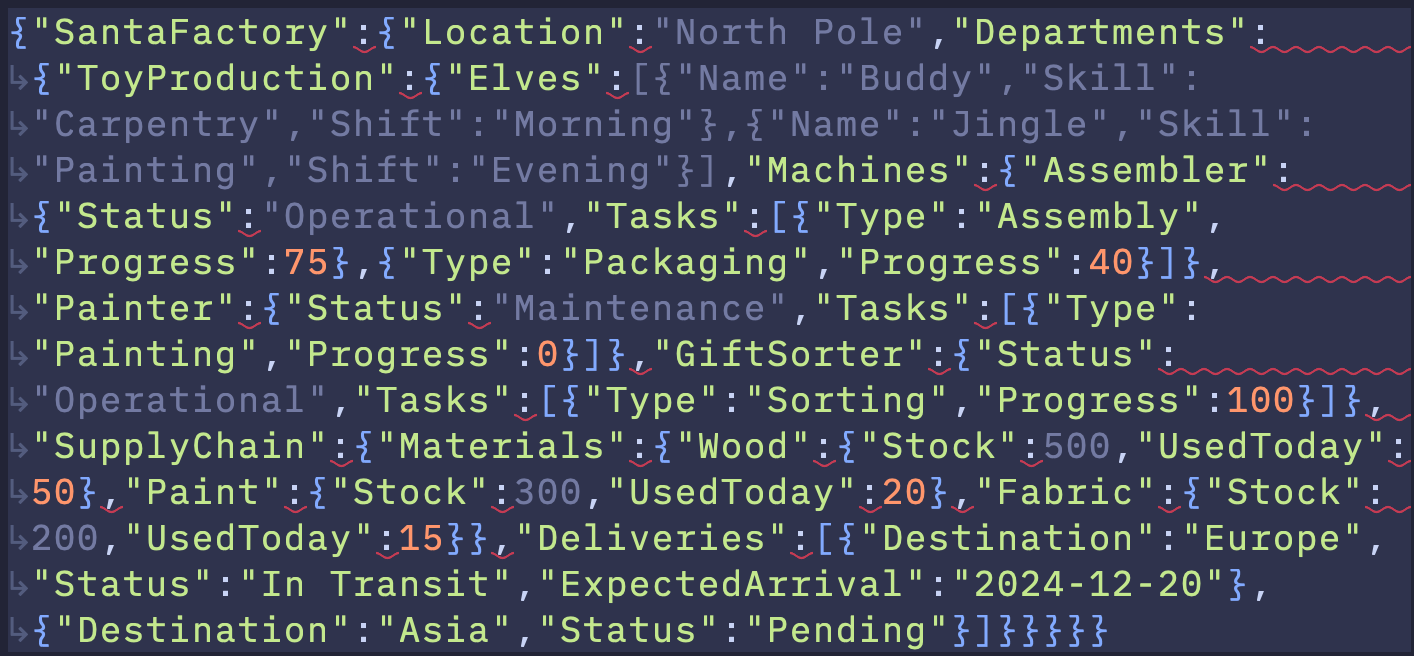
The curly braces aren’t balanced.
Asking it to pretty-print that same JSON, even with the errors present, consistently produces the same content but with corrected JSON.
You can occasionally even have the LLM iterate back-and-forth, asking it to print the JSON on a single-line, then pretty-printed, then single-line, and so forth where it will consistently get it wrong in the single-line version and always get it right in the pretty-printed version.
Key Advice
We’ve found that these aren’t anomalies or unique to any individual model – we see these same results across the spectrum of LLM foundation models and across a broad spectrum of tasks.
If we had to boil our best prompt engineering advice into a single morsel, it’d be that you should approach describing tasks for an LLM the same way that you would approach it for a human.
By making sure that instructions are clear and broken up into manageable steps, you will get more accurate and reliable results.
Learn more about LOGIC, Inc. at https://logic.inc