
Open-Sourcing Intent: An LLM-Powered Reranker Library That Explains Itself


We open-sourced intent today. It’s the library that powers semantic ranking and selection here at Logic.
It is an LLM-based reranker that offers ranking, filtering, and choice selection with a notable difference from most rerankers: it explains why it ranked things the way it did.
Most retrieval tools treat ranking as a black box. You put data in, and you get out numbers, you sort by the numbers. Intent is different. It generates a short, inspectable explanation for every single item it ranks, and then derives a relevance score based on that reasoning.
At Logic, we need to rank and select things for tons of use cases: template search, test cases, few-shot examples, onboarding docs, tool selection, etc. In the world of RAG and semantic search, we often rely on vector distance and rerankers to decide what context the AI sees.
While it’s nice to trust the math, the math misses the point sometimes.
If a traditional reranker gives a document a score of 0.92, why did it do that? Did it match a keyword? Did it misunderstand the user’s intent? Did it anchor on some oddity in the context? It’s opaque.
Worse yet, if you want to give explanations of the choices to your users, that number is meaningless.
Some teams try to solve this with “post-hoc” explanations. Asking a separate model call to look at the result and guess why it was chosen. This is dangerous. It’s akin to a Dungeon Master in a D&D campaign telling the party what happens after you roll the die; the DM will invent a plausible story for whatever number was rolled.
We wanted “pre-hoc” reasoning. We wanted the model to formulate a justification first, and then assign a score based on that reasoning.
Here is the difference between a standard reranker and an intent result:
Traditional Reranker:

Intent:

We’ve exposed three core methods that cover much of our retrieval needs at Logic, and likely much of yours.
1. Filtering
Sometimes you don’t want a ranked list; you just want an applicable subset. You can use intent.filter(…) to decide, for example, which tools an agent should have access to for a specific task.

The Result:
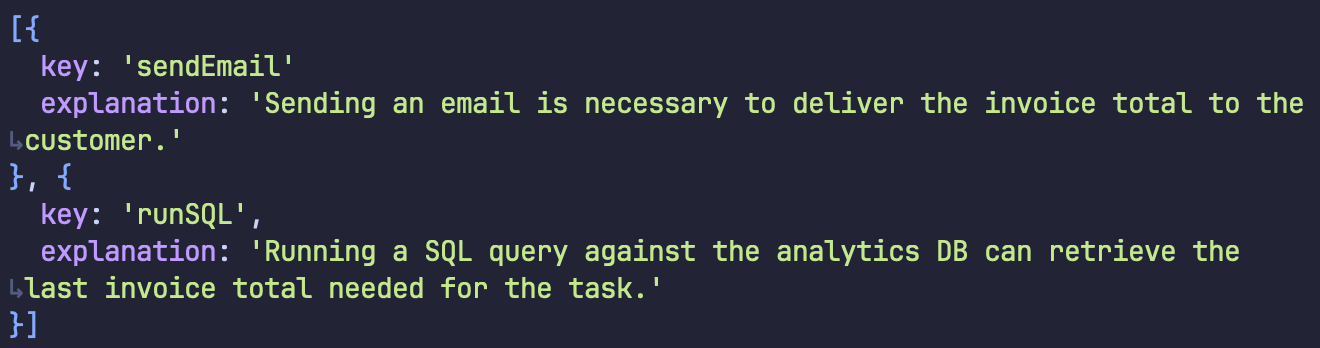
The model correctly ignored other tools (createInvoice and webSearch) because it reasoned they weren’t needed for this specific request.
2. Choosing
Sometimes you need exactly one winner. We can use intent.choice(…) for that. For example, if you wanted to dynamically pick an LLM to run a specific task based on fuzzy criteria.
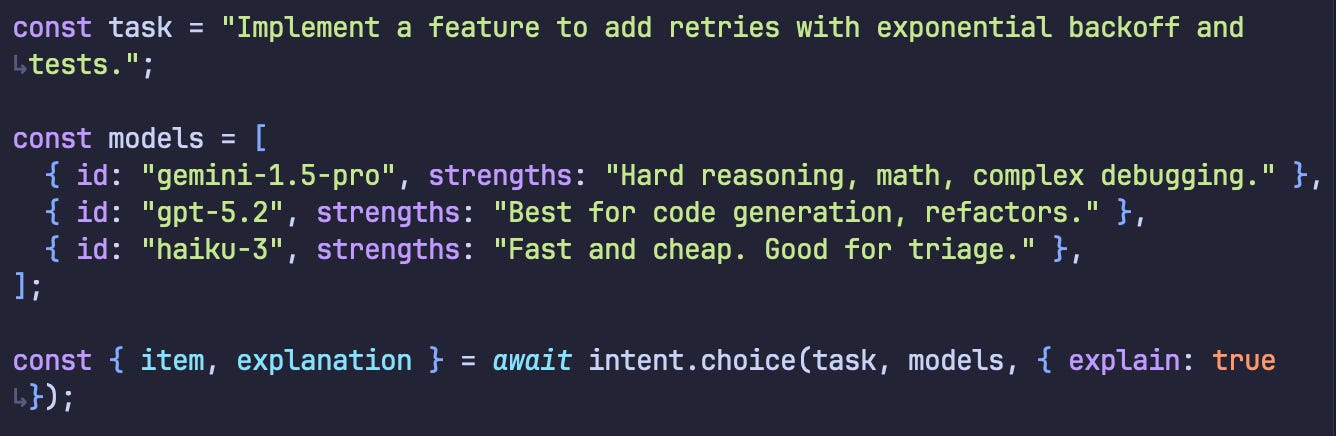
The Result:

3. Ranking
And of course, standard reranking with intent.rank(…). Because we can see the explanation, we can also share with our users why they’re seeing the thing they’re seeing.

The Result:

Addressing one elephant in the room, LLMs can be slow. Because of this we default to using open-source models hosted on Groq for speed. Groq is mind-boggling fast, giving instant answers.
The heavier-weight models are worth it, especially when the speed concern is addressed, because using an LLM offers far more flexibility than a fixed cross-encoder1. You don’t need to train a new model to change your ranking criteria. You can simply adjust the instructions and context.
If you are building RAG pipelines, agents, or search engines, you’d probably benefit from having the reasoning behind your ranking choices.
You can install intent via npm:
npm install @with-logic/intentAnd can check out the GitHub repo here: https://github.com/with-logic/intent.
Send us a note, we’d love to see what you build with it.
I wrote about traditional rerankers almost exactly a year ago here.